Незрелость ML в отрасли часто приводит к завышенным ожиданиям, которые часто сменяются разочарованием руководства и специалистов страховщика в потенциале машинного обучения для бизнеса.
 Традиции и ML
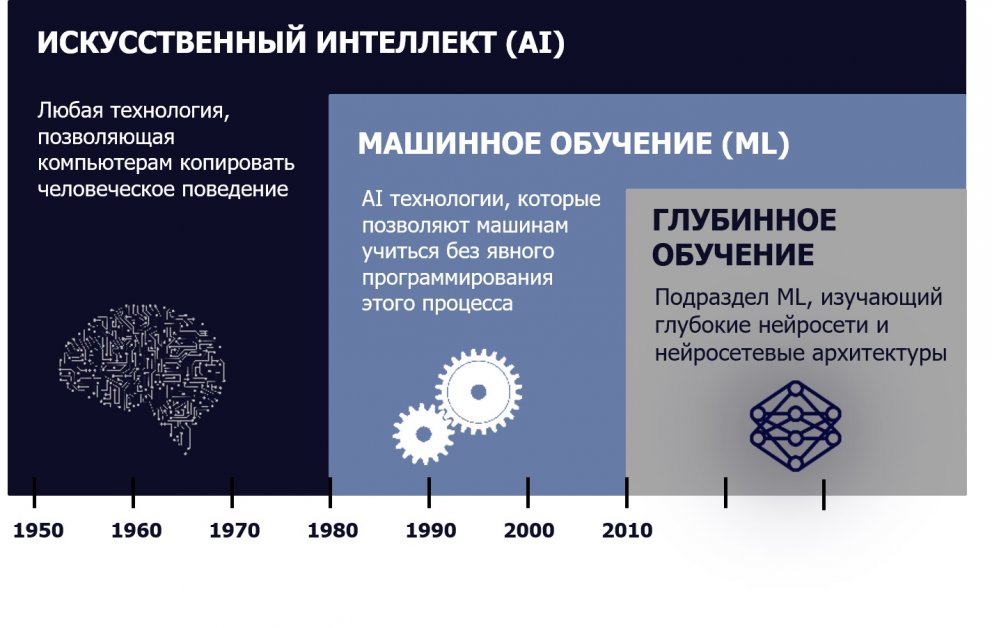
Традиции и MLМашинное обучение – это подраздел искусственного интеллекта (AI). Машинное обучение включает в себя множество подходов и методов, в том числе нейросети, линейную регрессию, бустинги, решающие деревья и случайные леса.
31 октября 2019 г. на Пятом ежегодном «Форуме лидеров страхового рынка» гендиректор «Зетта Страхования» Игорь Фатьянов выступит на сессии, посвященной искусственному интеллекту, роботам и insurtech. Подробнее
Большинство актуариев используют обобщенную линейную модель для анализа тарифных факторов, а она построена на методе линейной регрессии, который входит в область машинного обучения. Страховщики могут гордо смотреть в глаза прогрессу и приглашенным консультантам, поскольку для нас ML – это вполне традиционный для индустрии инструмент.
У методов машинного обучения есть много признаков группировки, но для практических целей ML-методы обычно группируются следующим образом:
- во-первых, по возможностям интерпретации решения. Какие-то методы четко оценивают влияние каждого фактора на итоговое решение, а другие выдают результат без оценки факторов влияния. Как правило, последние дают более точное решение. Для методов распознавания образов критерии принятия решения не так важны, а для тарифа наоборот;
- во-вторых, методы отличаются по пригодности для решения различных типов задач с данными различной структуры. Задачи по распознаванию изображения решаются одними алгоритмами, а другие помогают найти правильный тариф. Иногда методы комбинируются. Страховщики используют, как правило, случайный лес и прочие деревья.
ML: кейсы в страховании
Мы выделяем следующие направления:
1. Sales (продажи)
Поиск новых сегментов
Cross/up sale
Пролонгация и предсказание оттока клиентов.
Персонифицированное отношение к клиентам – направление, по которому идут многие компании, где-то, как в розничном банкинге, это уже является одним из важных конкурентных преимуществ. Для того чтобы решить успешно эту задачу, требуется понять поведение и потребности каждого конкретного клиента.
В этом нам помогают задачи сегментации клиентов по многим факторам: соцдем, информация о страховых продуктах, которыми клиент пользуется, история его обращений через службу поддержки и напрямую через филиалы компании и т.д. Это многофакторная модель с сотнями тысяч прецедентов и эффективно построить ее можно только силами высококвалифицированных аналитиков и экспертов с применением сложного математического аппарата, в том числе и с применением методов Машинного обучения.
После решения задач сегментации клиентов, надо доработать полученную модель, находя группы лояльных и нелояльных клиентов (предсказание оттока), или находя группы людей, которые с большой долей вероятности готовы на покупку еще одного страхового продуктов (cross-sale или next-best-offer).
2. Underwriting (андеррайтинг)
Создание / оптимизация рисковых моделей
Предсказание убыточности клиента.
Оценка рисков – крайне важный процесс для страхового бизнеса, требующий постоянного развития методов и инструментария.
Тут есть два важных, дополняющих друг друга, направления.
- Первое: обогащение имеющихся о клиенте данных (с его согласия), например, данными из БКИ.
- Второе: применение интерпретируемых алгоритмов Машинного обучения, таких как линейные классификаторы, леса решений, метод главных компонент.
Тем не менее здесь у новых ML методов есть своя ниша. Дело в том, что перерасчет ОЛМ и поиск новых факторов – это очень трудоемкая задача. Вместе с тем, другие интерпретируемые методы обрабатывают новые данные и обучаются быстрее, реагируя на изменения. Это помогает андеррайтерам как в поиске новых факторов, улучшающих рисковую модель, так и искать риски, недооцененные ОЛМ.
3. Antifraud. Борьба с мошенничеством
Злонамеренное мошенничество, к сожалению, имеет место быть во многих областях нашей жизни. Борьба с ним часто неприятный, но необходимый процесс.
Для эффективного мониторинга все новых и новых мошеннических схем требуется отслеживать и обрабатывать все большее количество данных. Как и в случае со скоринговыми моделями, автоматизация и ML помогает поддерживать нужную скорость процесса обнаружения мошенничества и в автоматическом режиме, за сотые секунды оценивать вероятность мошенничества по каждому конкретному страховому договору. Такая система применяется в Турции, где работа с данными по мошенникам централизована на базе единого бюро страховых историй.
Кроме того, есть и кросс-секторальные ML-кейсы, которые могут быть использованы в страховании. Например, семантический анализ информационного поля (СМИ, публичной части социальных сетей) с целью превентивного обнаружения информационных атак, анализа отношения к бренду или оптимизации маркетинговых компаний. Эти задачи могут быть решены с помощью современного NLP (Natural Language Processing – подраздел машинного обучения, занимающийся лингвистическими задачами).
Тем не менее, на российском рынке убытки по мошенничеству в каждой отдельно взятой компании еще не сформировали достаточного массива данных для построения модели способной самостоятельно предсказать мошенничество с приемлемой точностью. До момента запуска закона о бюро страховых историй и технического перевооружения ВСС в этой области оперативное чутье скорее всего будет существенно превосходить искусственный интеллект. Текущие технические решения в основном помогают фильтровать небольшие убытки перед ручной проверкой по «красным флагам».
Общий итог
ML в страховании, имеет свою практику применения, новые методы анализа и появления дополнительных источников данных стали поводом переосмыслить роль математических методов в нашей отрасли. На текущем этапе развития ML – это венчурная инвестиция. Как и любому венчурному предприятию, для успешного внедрения машинного обучения требуется специальная «среда».
Это среда состоит из данных, специальных программных средств, культуры работы с данными, а главное, сотрудников с компетенциями в анализе данных и предметной области. Именно над развитием такой среды мы в «Зетта Страхование» активно работаем в настоящее время.
Интересно, что из описанного реально реализовано в Зетта и с какими практическими задачами сейчас работает компания?
чего достигла от применения описываемых методов?
В принцнипе по всем трем направлениям и работаем. Статья основана на реальных событиях . Наиболее сложно сделать модель по мошенничеству. По андеррайтингу модель действительно «подсвечивает» новые сегменты относительно других методов, но нельзя сказать что дала прямо прорыв…
. Наиболее сложно сделать модель по мошенничеству. По андеррайтингу модель действительно «подсвечивает» новые сегменты относительно других методов, но нельзя сказать что дала прямо прорыв…
«Например, модель, которая выявляет мошенников с точностью 99% может быть очень плохой, если обозначает мошенническими 90% убытков.» Ну тут все понятно это и выединого
Яйца не стоит. Страховая может и без машинного обучения все приравнивать к мошенничеству. Просто в случае с программой будет(ну это не мы, это программа).
Ну, если такой подход принимать, то любой метод можно списать. Если принимать в компании отговорки типа «это не мы, это....», то лучше вообще ничего не делать.
Вообще речь шла о способах оценки эффективности моделей, если Вам все понятно, то я рад, что Вы смогли разобраться в таком вопросе, как сравнение различных мат моделей, построенных на ML алгоритмах. Приведенный пример на крайних значениях акцентирует проблематику. На практике предполагается сравнить работу ручным методом и модель которая находит, например, 80% случаев мошенничества, но дает 30% ошибок. Ответ уже не так очевиден.
Давайте так, мы же взрослые люди? И не будем писать глупости. Я еще раз напишу. По каким признакам будет ML определять что мошенничество это или нет? По косвенным? Таким как безлюдное место и темное время суток? Вот я то точно не наивный а вот за других отвечать не буду.)) А теперь если вы просвещенный человек в этом вопросе вы наверное аргументируете свой ответ, а не общими фразами будете кидаться. Единственный признак который ВОЗМОЖНО можно подтянуть за признак мошенника это большое количество Дтп от 3 и более за ГОД. И то в наше время когда количество машин увеличивается то и шанс попасть в дтп увеличивается ну это нормально как бы. Вероятность возрастает.
Вам бы стоило сначала прочитать, что есть ML и какие у этого способа минусы. Ваш абсолютно некорректен. Скорее всего причина такой ситуации — отсутствие адекватных данных для тренировок.
Определение мошенничества это всегда косвенный признак.Давно не видел заявлений на которых указано «это мошенничество. прошу рассмотреть в особом порядке, решение суда приложено».
по факту ML работает именно от мелких признаков, но не с каждым отдельно а совокупностью. конечно дтп без свидетелей не показатель само по себе, но если таких настораживающих фактов накапливается десяток, то мошенничеством можно считать вполне вероятным.Ds,jh таких факторов и сбор информации по ним всегда трудоемкий процесс, поэтому его ручное исполнение для некрупных убытков стараются автоматизировать. область новая, нужна очень большая база для обучения. Надеюсь с БСИ придумаем что-нибудь.
Судя по формату вопроса Вы хотите услышать автоматизируемый признак, который сам по себе значит много. Такие тоже есть, например, связи в соцсетях, полис полного каско в двух и более СК, тоталь в прошлом периоде, пересечение границы с подлинными документами и.т.д. На это есть тоже модный ярлык(Big Data и все такое). Впрочем пробив по базам все используют, соцсети реже. Но это не ML.
Кстати для определения мошенничества частотное ДТП не самый лучший показатель, если это в одной СК. По такому признаку скорее будет видно коммерческое использование ТС, чем преднамеренный ущерб.
Выявить предполагаемое, а не свершившееся, мошенничество можно только по косвенным признакам. И это про мл. А вот работа уже с случившимися событиями — это работа ручками, с доказательной базой и фактами,
но после драки кулаками не машут и все внимание стоит уделять мощной защите на входе. Но мешает План продаж
Выше пропущено слово «вопрос»
Машин лёрнинг — это, конечно, хорошо, но когда генеральный директор сам пишет статьи, да ещё и в комментариях отвечает — это ещё круче… Респект…
«Кстати для определения мошенничества частотное ДТП не самый лучший показатель, если это в одной СК. По такому признаку скорее будет видно коммерческое использование ТС, чем преднамеренный ущерб.» Ну коммерческое использование обычно идет на организацию страховка, а вот когда человек часто попадает в дтп на личном авто то тогда стоит обратить внимание, а если идет частая совокупность у ОДНОГО и того же человека. Тогда да, стоит бить тревогу. Но опять же нужна доказательная база. И тогда и только тогда в суде уже указывать что это было мошенничество. А общие фразы в статистике мошенничество и все прочее это больше звучит как клевета. Когда типа выявлено 1200 случаев мошенничества а уголовных дел 100 из них Обвинительных приговоров 5. Вы серьезно? Я бы на месте тех кого обвинили в мошенничестве еще бы за клевету денег содрал бы.)) Потому как если 1200 мошеннических случаев а доказанных всего 5 то 1195 случаев не являются мошенническими.
Публикуя статьи мы рассчитываем на вашу экспертность, а не теоретические рассуждения.
Расскажите практический кейс, из вашей практики. Хотя бы на примере автострахования. Возможно даже уже затронутая тема мошенничества. Или критерии коррекции среднего тарифа.
По каким признакам обучаете продакт, какой эффект получаете сегодня, ближайшие цели? Чему больше всего удивились, инсайты?
И не обижайтесь, тереть коменты не самое почетное занятие, тем более когда на рынке действительно есть мнение что Зетта не авангардист. Ну так и Москва не сразу строилась.
SerG, наверное вы хотели сказать, что рассчитываете «читая» статьи. Все-таки публикует АСН, рассчитывая, видимо, на читательский интерес. Опять же каждый человек разное ищет. Коменты вроде не затирает, не переживайте.

Кстати, в части инсайтов и практического применения АСН сделала очень хорошую статью. На случай, если и там не найдете практического опыта, добавлю пару слов от себя.
Как я уже говорил, машинное обучение включает в себя метод линейной регрессии, который очень широко использовался страховщиками последние 10-20 лет в рамках ОЛМ метода. На эту тему есть множество статей.
Если говорить о новых моделях, то пока главный инсайт в том, что для тарификации ОЛМ с большими данными работает более эффективно, чем новые модели.
Даже нейросети для страховщиков не стали прорывом, несмотря на то, что в области распознавания изображений они совершили революцию.
Было несколько инсайтов в области сегментации, но не сказать чтобы прорывные. публиковать их, наверное, рановато, пока не выжали из них всю прибыль
Ближайшие цели состоят в повышении качества моделей. Мы не пытаемся продвигать модели ради моделей, показушный авангардизм действительно не наш конек.
Мы прагматики — пробуем все, но внедряем самое эффективное. Могу с гордостью сказать, что нет ни одной работающей инновационной технологии на рынке, которую мы бы не применили на практике одними из первых.
Борьба с мошейниками должна быть на этапе страхования, не брать их. Пока не будет общей базы СК по страховым история — это мечта. По выявлению самого факта, тут стандартный чек лист. Однако работая в этой сфере уже очень долго, сейчас в компании топ 10 трасологов, скажу что первые мошейники это сотрудники безопасности… А потом уже клиенты, судьи, эксперты.
Войдите через свой аккаунт в соц. сетях или почтовых сервисах